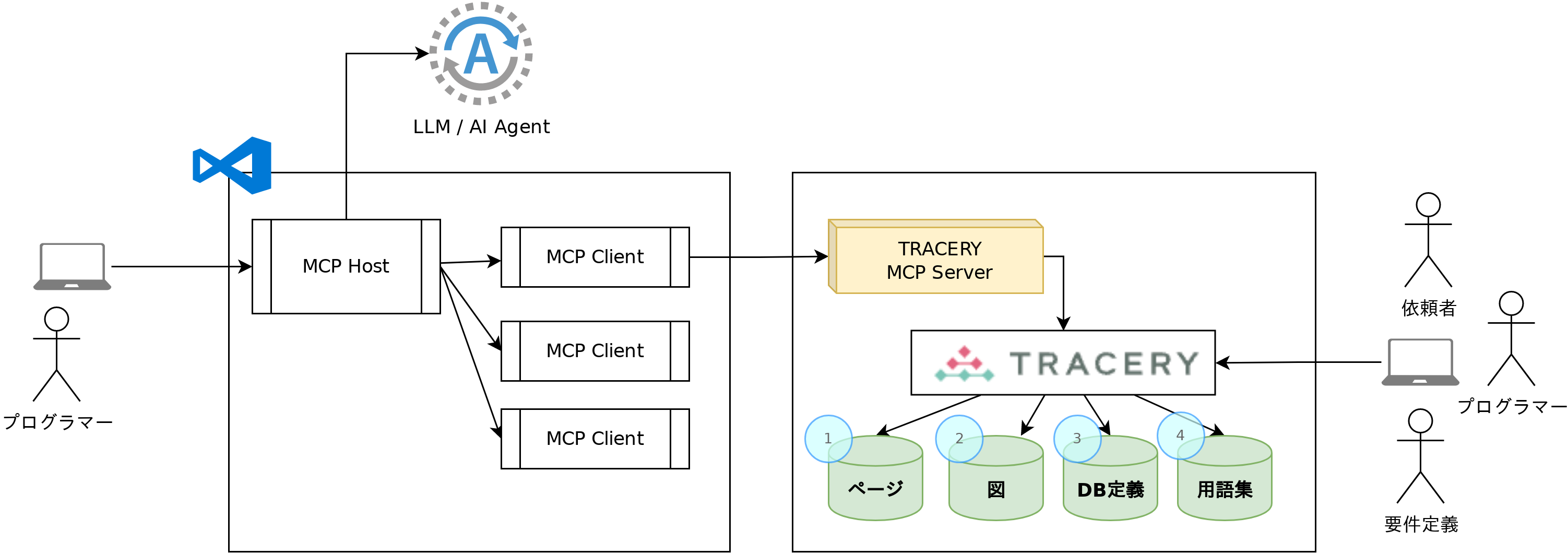
MCPでAIエージェントからTRACERYにアクセスする¶
TRACERYのMCPサーバー機能を利用することで、TRACERYをシステム開発における知識を保存するバックエンドとして利用できます。
以下の記事も合わせてご参照ください。
MCP連携で加速するAI駆動開発 - その1:TRACERYがMCP対応した理由とその背景 - TRACERY Lab.(トレラボ)
MCP連携で加速するAI駆動開発 - その2:設計書からAPIまで──TRACERY連携の実演 - TRACERY Lab.(トレラボ)
MCP連携機能とAIコーディングの活用〜TRACERY開発者がPodcastで解説 - TRACERY Lab.(トレラボ)
AI駆動開発におけるMCPの役割¶
AI駆動開発は、コードの自動生成で開発を加速させる一方、AIが生成したドキュメントや知見がコードリポジトリー内に留まり、開発者以外が参照しにくいという問題を引き起こしがちです。
この課題を解決するのが、AIと外部ツールを連携させる共通仕様である MCP(Model Context Protocol) と、MCPサーバー機能を提供するTRACERYです。TRACERY MCPを利用することで、ドキュメントや設計情報を一元管理し、最新のドキュメントをビジネスオーナーから開発者まで全員が従来通りTRACERY上で共有できるようになります。
ビジネスオーナーのメリット:透明性とリスク低減¶
AI駆動開発によってドキュメントが取り残される問題は、チーム外での情報共有を困難にします。たとえば、開発経緯や設計情報がリポジトリー内のファイルにだけ記録されると、コードを直接扱わない関係者(プロジェクトマネージャーや要件定義者など)が現状を把握するのが難しくなります。
TRACERY MCPは、開発チームが作成した設計情報やドキュメントを、TRACERYのWebインタフェース上でビジネスオーナーや要件策定者も簡単に参照できる状態を維持します。これにより、プロジェクトの透明性が確保され、意思決定が迅速になります。さらに、TRACERYのトレーサビリティ機能を活用することで、変更による影響範囲を正確に把握し、プロジェクト全体のリスクを低減できます。
知識の一元管理: 人間向けとAIエージェント向けのストック情報が分断されることなく、TRACERYで一元的に管理されます。
参照可能性の向上: 開発者以外もTRACERY上の設計情報に容易にアクセスできるようになります。
トレーサビリティの活用: AIエージェントによる変更の履歴を確認できます。
TRACERY MCPは、AI駆動開発のスピードを保ちながら、チーム内外との知識共有を両立させるためのソリューションです。
開発者のメリット:生産性の向上¶
AI駆動開発の現場で発生しがちな、以下の課題を解決します。
AIエージェントが長いコンテキストを忘れてしまう
設計情報がソースコードリポジトリーに限定され開発者以外が参照、更新しづらい
AIエージェントがMCP経由でTRACERYにアクセスすることで、常に最新のドキュメントや設計情報を参照できるようになります。また、AIエージェントが設計や実装の結果、コードの現状をMCP経由でTRACERYのドキュメントに反映できます。これにより、AIと人間が同じ知識を共有し、開発の手戻りを減らして生産性を高めることができます。
知見の再利用: 設計や実装の途中経過、ルールなどをTRACERYに保存することで、次の開発サイクルでAIがこれらの知見を再利用しやすくなります。
トレーサビリティの活用: TRACERYのバックリンク機能などのトレーサビリティ情報をAIにコンテキストとして渡すことで、変更による影響範囲を正確に把握させ、開発の安全性を高めることができます。
TRACERY MCPが提供する機能¶
MCP(Model Context Protocol)は、AIエージェントと外部ツール・データ接続のための共通仕様です。 TRACERY MCP機能によって、AIエージェントはTRACERYに蓄積された要件や設計などのドキュメント、データベース定義、用語集などのシステム開発の知識を利用できるようになります。
MCPサーバーには、クライアントと同じ環境で動作するローカルMCPサーバーと、外部でホスティングされるリモートMCPサーバーの2種類があります。TRACERYはリモートMCPサーバーを提供しています。
ローカルMCPサーバー: 利用者自身でインストールやセットアップが必要となります。
リモートMCPサーバー: 外部でホスティングされているため、利用者はURLを入力して認証を行うだけで、簡単に使い始めることができます。
MCPサーバーのアーキテクチャーについて、詳しくは以下のサイトを参照してください。
MCP連携手順¶
TRACERY MCPサーバーをAIクライアントに接続する手順を説明します。 Streamable HTTPトランスポート(transport=http)でのリモートMCPサーバー接続に対応しているツールから利用できます。
ここでは、Visual Studio Code(バージョン1.101以降)を例に説明します。
1. TRACERYプロジェクトの準備¶
連携したいTRACERYプロジェクトを用意します。
2. VSCodeにMCPサーバーを追加¶
Visual Studio CodeなどのMCPクライアントに、TRACERY MCPサーバーのURLを追加します。 TRACERY MCPサーバーのURLは、以下の形式です。
Name:
tracery(任意ですが、以下の説明ではこの名称を使用します)URL:
https://<ワークスペースのサブドメイン>.tracery.jp/mcp/Transport:
http(Streamable HTTP)
設定方法の詳細は、お使いのAIクライアントのドキュメントを参照してください。
Visual Studio Code: Use MCP servers in VS Code
Claude Code: MCP コネクタ - Claude Docs
3. 初回アクセス時に認証を行う¶
クライアントからTRACERY MCPサーバーに初めてアクセスする際、認証が必要です。 クライアントからブラウザーが開かれ、TRACERYの認可画面が表示されます。
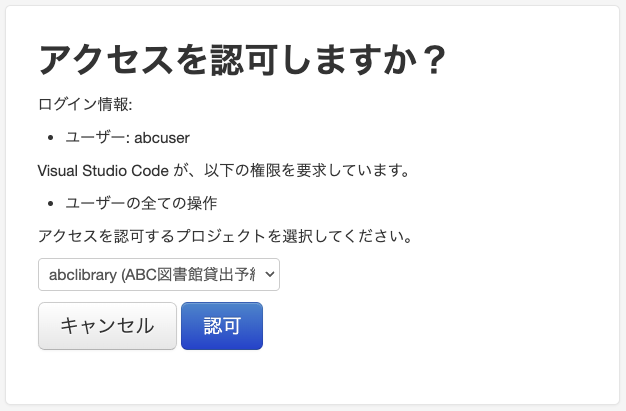
ここで、どのプロジェクトを利用するかを選択し、認可ボタンを押下します。 認可後、ブラウザーからクライアントに認可情報が渡され、TRACERY MCPサーバーに接続されます。
接続確認手順¶
MCPサーバーが正しく接続されているかを確認します。
AIへの確認プロンプト¶
AIクライアントのチャット機能などで、AIエージェントに以下のプロンプトを送信します。
#tracery で使えるMCPツールを確認してください
これにより、TRACERY MCPサーバーをAIクライアントに明示し、認識状況を確認できます。
Visual Studio Codeでは、 # の入力で、MCPサーバーやツール、ファイル、関数などを指定できます。
Claude Codeでは、 / や @ の入力で指定できます。
プロンプト例¶
TRACERYのストック情報を活用するためのプロンプト例を紹介します。
データベース定義の論理名設定とコメント追加¶
既存のモデル定義ファイルを元に、データベース定義に論理名とコメント(説明、概要)を設定してもらうプロンプトです。概要には、論理名を元にした用途や、INDEX、UNIQUEなどの制約を付けた理由などの補足情報を含めることができます。
なお、あらかじめテーブル定義をデータベース管理機能にインポートしておくと効率的です。
プロンプト例
- #get_databases でDB定義を確認してください
- #models.py の内容を元に論理名を #update_column 等で設定してください。
- また、DB定義にコメント(説明、概要)を設定してください。
- 概要には、論理名を元にどのような用途なのか追加情報を記載してください。
- 概要はidやFKなど明確なものには不要ですが、説明が必要であれば設定してください。
- INDEXやUNIQUE等の制約を付けた理由を伝える必要があれば、概要に追記してください。
システム全体の用語登録¶
DB定義とソースコードに基づき、システム全体の用語集を登録してもらうプロンプトです。対象ドメインの専門用語を優先し、カテゴリー分けやコーディング用名称(小文字のスネークケース)の定義も指示できます。
プロンプト例
- DB定義とソースコードに基づいて、用語を登録してください。
- 用語はカテゴリーごとに分類し、関連する用語をグループ化してください。
- 用語のうち、優先度が高いのは、対象ドメインの専門用語です。
- 他にも、システム用語や業務用語など、関連する用語を登録してください。
- 開発関連の用語は知名度の低いものだけでOK. たとえばDjangoやPythonなどの有名なものは登録しないでください。
- コーディング用名称は小文字のスネークケースです。
要件に基づいたAPI設計と実装¶
TRACERY上の要件を参照し、必要なAPIのテーブル設計、API設計、そして実装までを依頼するプロンプトです。中間段階で人間が確認・手直しできるよう、ローカルファイルへの書き出しを指示することもできます。
プロンプト例
- TRACERYで、要件「書籍お気に入り機能」を確認して、要件を満たすのに必要なAPIを教えてください。
- まずはテーブル設計を行って、 `design.md` ファイルに書いてください。
- それを元にAPI設計を `design.md` ファイルに書いてください。
ここで、必要であれば design.md を手直しします。
- この内容で実装してください。
実装結果のドキュメント化¶
実装結果を元に、DB設計、API設計、新しい用語をTRACERYに登録してもらうプロンプトです。
プロンプト例
- 実装した結果をまとめて、TRACERYに登録してください。
- 「DB設計」はデータベース定義に反映してください。
- 「API設計」は、メソッドxエンドポイント単位で分けて、「API設計」ページカテゴリーにページ登録してください。
- 「新しい用語」は、 #create_term コマンドで登録してください。
利用上の注意点¶
プロンプト実行時の挙動¶
AIエージェントが実行するアクションの中には、TRACERY上の情報更新などの破壊的な操作を伴うものもあります。たとえば、データベース定義の更新などです。このような操作を行う前に、AIは実行内容をユーザーに確認するプロンプトを表示します。実行許可を判断し、操作を進めてください。
ハルシネーションと最終確認の重要性¶
AIが生成する内容は、提供されたコンテキストに沿うよう制御されています。しかし、ハルシネーション(AIによる事実に基づかない情報の生成)が発生する可能性をゼロにはできません。このため、AIの提案を必ず確認してください。APIの設計案など重要なアウトプットについては、必ず人間が内容を確認し、必要に応じて修正してください。
関連記事¶
以下の記事も合わせてご参照ください。
